
Umi-OCR v2.0.1–开源免费离线OCR文字识别软件正式版


Umi-OCR 是一款免费的离线OCR文字识别工具,它可以将图像中的文字扫描提取出来,将其转化为可编辑的文本,支持批量OCR,支持19种协议二维码图片解析,生成二维码。内置多国语言模型库。
开源地址: https://github.com/hiroi-sora/Umi-OC
目前仅支持Windows平台


标签页
Umi-OCR由一系列灵活好用的标签页组成。您可按照自己的喜好,打开需要的标签页。
标签栏左上角可以窗口置顶。右上角能够锁定标签页顺序和位置,以防止日常使用中误触关闭标签页。

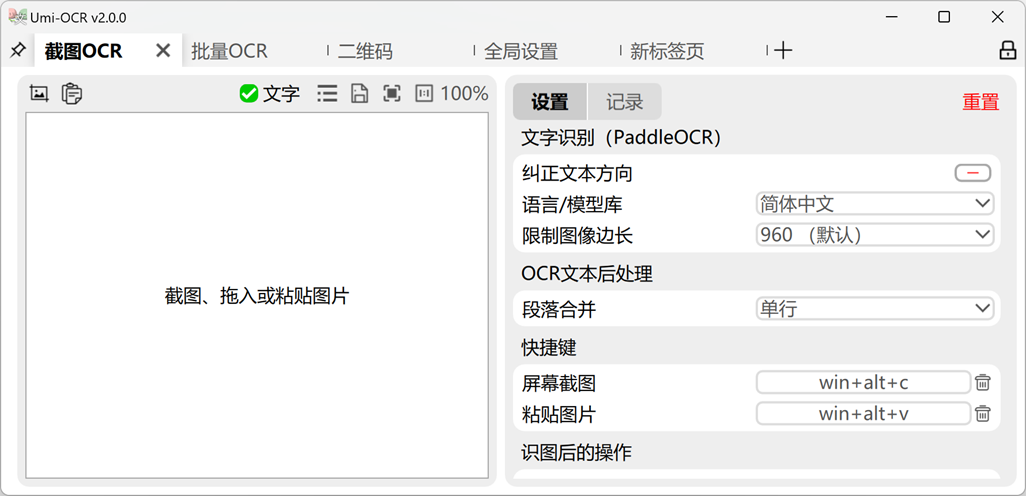
截图OCR
打开这一页后,就可以用快捷键唤起截图,识别图中的文字。
- 左侧的图片预览栏,可直接用鼠标划选复制。
- 右侧的识别记录栏,可以编辑文字,允许划选多个记录复制。
- 也支持在别处复制图片,粘贴到Umi-OCR进行识别。

段落合并
关于 OCR文本后处理 – 段落合并:
可以整理OCR结果的排版和顺序,使文本更适合阅读和使用。预设方案:
- 单行:合并同一行的文字适绝部情景。
- 多行–自然段:智能识别、合并属于同一段落的文字,适合绝大部分情景,如上图所示。
- 多行–代码段尽可还原始排版的缩进与空格。适合识别代码片段,或需要保留空格的场景。
- 竖排:适合竖排排版。需要与同样支持竖排识别的模型库配合使用。

批量OCR
这一页支持批量导入本地图片并识别。
- 识别内容可以保存为 txt / jsonl / md / csv(Excel) 等多种格式。
- 支持文本后处理技术,能识别属于同一自然段的文字,并将其合并。还支持代码段、竖排文本等多种处理方案。
- 没有数量上限,可一次性导入几百张图片进行任务。
- 支持任务完成后自动关机/待机。

忽略区域
关于 OCR文本后处理 – 忽略区域:
批量OCR中的一种特殊功能,适用于排除图片中的不想要的文字。
- 在批量识别页的右栏设置中可进入忽略区域编辑器。
- 如上方样例,图片顶部和右下角存在多个水印 / LOGO。如果批量识别这类图片,水印会对识别结果造成干扰。
- 按住右键,绘制多个矩形框。这些区域内的文字将在任务中被忽略。
- 请尽量将矩形框画得大一些,完全包裹住水印所有可能出现的位置。

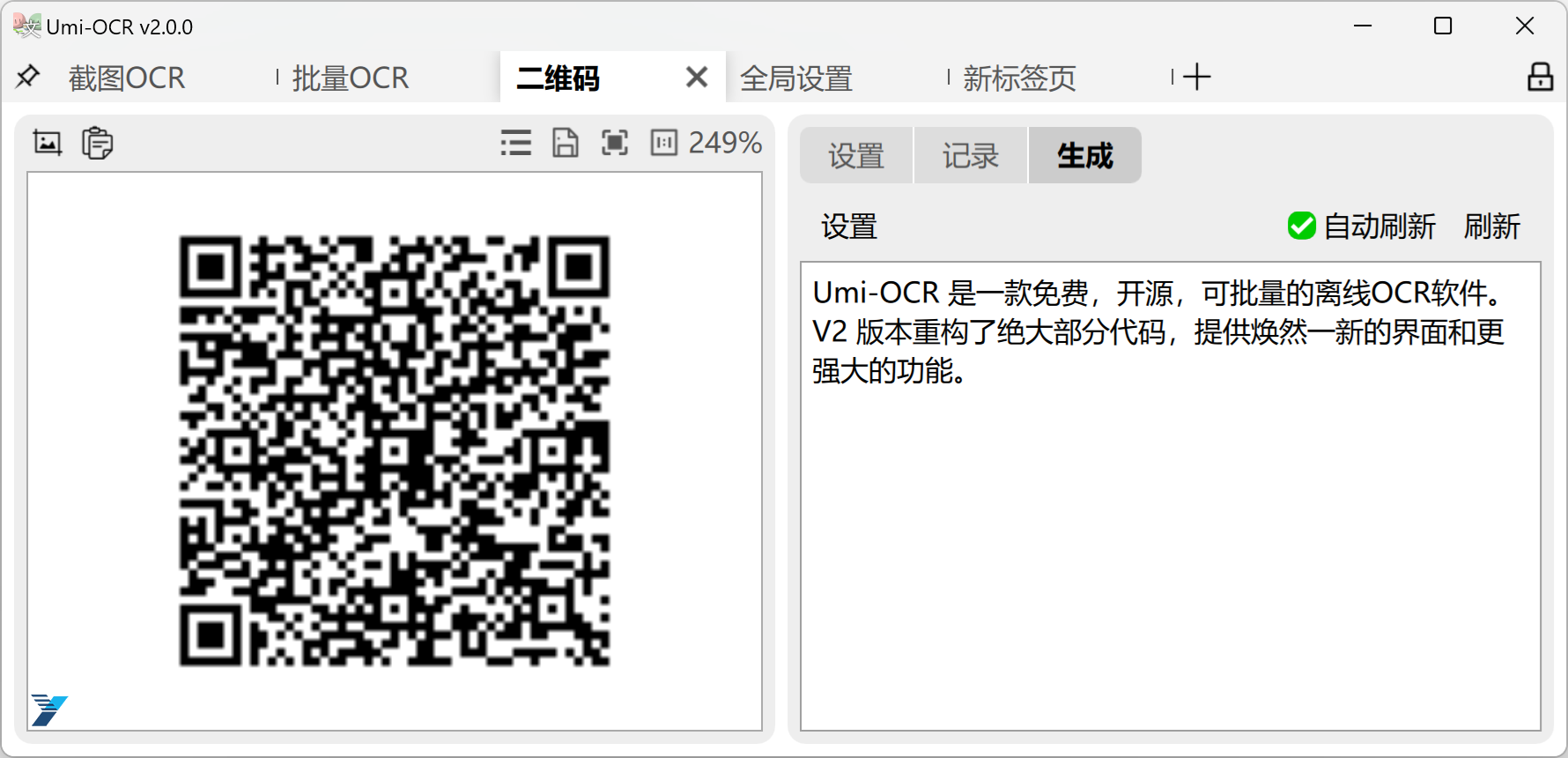
二维码扫描:
- 可截图/粘贴/拖入本地图片,读取其中的二维码、条形码。
- 支持一图多码。
- 支持19种协议,如下
Aztec,Codabar,Code128,Code39,Code93,DataBar,DataBarExpanded,DataMatrix,EAN13,EAN8,ITF,LinearCodes,MatrixCodes,MaxiCode,MicroQRCode,PDF417,QRCode,UPCA,UPCE,

生成码:
- 输入文本,生成二维码图片。
- 支持19种协议和纠错等级等参数。

原创文章,作者:adminz,如若转载,请注明出处:https://zj.syuanz.top/3250.html
相关推荐
-
Windows Defender 检查和关闭工具WDControl_v1.7.0
想直接关闭直接看文字后半段 下面是关闭的方法 临时手动关闭: 或 Win + R 打开运行 输入 windowsdefender://Threatsetting…
-
Acrobat PRO DC 23.001.20174 破解版32位
Acrobat DC 2023中文破解版是Adobe公司继Acrobat XI之后推出的又一款全新PDF专业制作软件.Adobe Acrobat Pro DC将世界上最优秀的PDF…
-
Visual C++运行库合集轻量版23年03月版v69
Microsoft Visual C++ Redistributable(简称MSVC,VB/VC,VC运行库)系统运行库是Windows操作系统应用…
-
福昕高级PDF编辑器专业版 v2024.2.0.25138 绿色精简
修改说明 – 福昕高级PDF编辑器破解专业版,绿色精简,移除不常用组件和插件– 采用官方最新自定义向导工具功能配置生成器优化了默认个性化选项:├—禁用:首页…
-
微信电脑版 v3.9.9.43 多开防撤回绿色版
修改说明 绿色制作 防撤回 多开支持 软件截图 更新日志 – 新增锁定功能、最近搜索记录 (3.9.5)– 正在发送中的消息可直接撤回 (3.9.5)…
-
XMind 2024 中文破解版 v24.01.14361 特别版
XMind 2024中文破解版 (XMind思维导图2024) 是一款风靡全球的头脑风暴和思维导图软件,为激发灵感和创意而生.在国内使用广泛,拥有强大的功能,包括思维管理,商务演示,与办公软件协同工作等功能.XMind中文版采用全球先进的Eclipse RCP软件架构,是集思维导图.头脑风暴,脑图,心智图,模板图库一体的可视化效率工具.
-
uBlock Origin , 最好用的浏览器广告过滤扩展
扩展界面按钮功能:超大按钮:启动和停用扩展按钮闪电图标:进入元素临时移除模式吸管图标:进入元素选择模式列表图标:进入网络请求记录器面板图标:进入uBlock的控制面板 扩展界面底部…
-
雷电模拟器9(64) v9.0.64.1 去广告绿色纯净版
玩电脑手游模拟器安卓版首选雷电模拟器9.0最新版采用Android 9版本内核.雷电安卓模拟器最新版,支持OpenGL3.1模式3D渲染,游戏稳定多开无压力,提供谷歌安装器,一键宏按键,脚本录制,多开分屏同步器等功能.
-
跑满百度云盘下载神器 我不是盘神 PanDownload 复活了!
自从 PanDownload 被处理之后,一直没有超越它的可替代的应用出来。 但是最近,竟然有人接盘了!重新制作上线推出了更加强劲的复活版! 放张图,大家先感受下 10MB/s!!…
-
Adobe Flash Player纯净版!拒绝中国特供版!拒绝垃圾弹窗!拒绝垃圾广告!
目前国内的公司在代理Adobe Flash Player,属于中国特供版。但特供版使用时候,有流氓广告,具体来说: 后台存在广告服务 弹出广告窗口 捆绑流氓软件的行为 国际版不存在…